I started playing around with Obsidian a little over a year ago and I’ve been hooked ever since. It has become my main note-taking app, my main writing app, as well as my index for all of the resources I may want to pull from when I write for my main website.
Logos is my main Bible/theological studies app. I have a few thousand resources in it and would love to be able to reference these in my writings as well as know what I have on hand when I begin studying a topic and writing on it.
This article presumes you already have a basic understanding of Obsidian and Logos. If you would like for me to write more about either of these two tools, leave a comment below.
Here is the high-level process:
- Install the JSON/CSV Importer plugin for Obsidian
- Export your library from Logos
- Prepare your import file
- Create a Handlebar template in Obsidian (I have provided mine).
- Test Import until happy
- Final import
Before getting started, you will also need the Templater plugin. And the Dataview plugin will be necessary for you to get the most out of your imported collection.
Install The JSON/CSV Importer Plugin
When you search the Community plugins for “JSON” is should be the first one that comes up
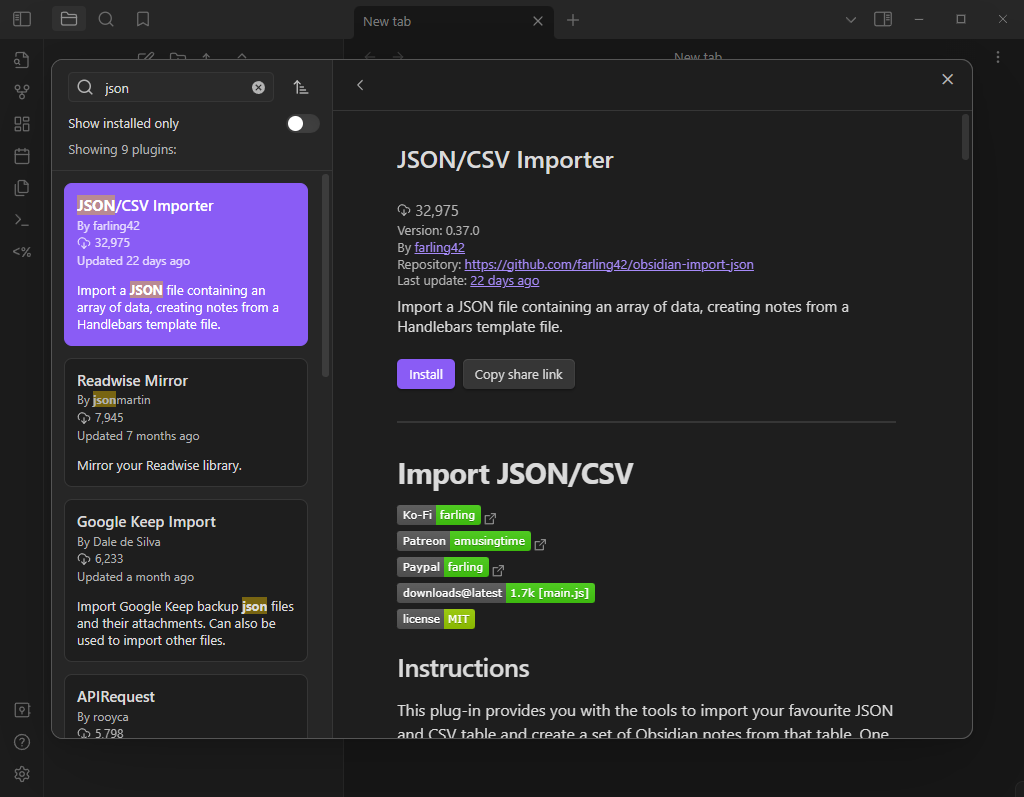
There aren’t any options to configure after it’s installed so this part is done.
Export Your Logos Library
- IN Logos, click on the Library icon in the left navigation and drag it onto the Home screen. This has to be done to get the Print/Export option to appear. Just opening the Library window won’t do it.
- Click the three dots in the top right corner and choose Print/Export…
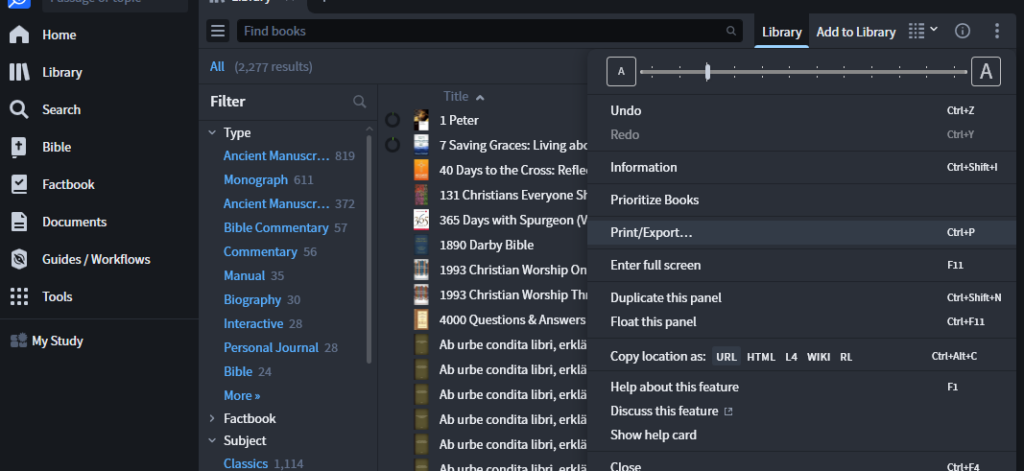
3. Under the Export section, choose Spreadsheet.
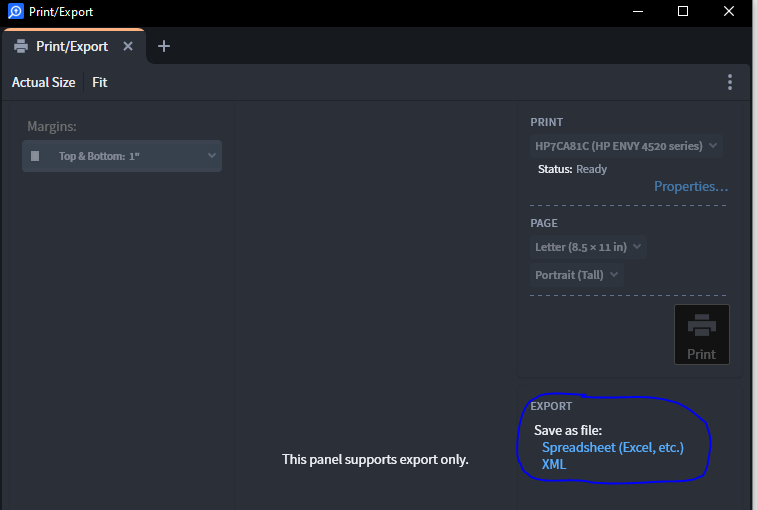
4. In the “Save As dialog, change the file type from XML to CSV. This will export your entire library.
Prepare Your Import File
Here are a few things you may want to keep in mind before importing the file. First, the import plugin does not allow for spaces in the field names. You will need to remove those in the first row.
Second, the importer does not like semicolons (“;”). Logos uses semicolons as a delimiter in its fields that can contain lists. For example, the “MyTags” and “CommunityTags” fields. If any rows have semicolons in them, the import will fail. They need to be replaced with commas and the entire list in the field needs to be enclosed by quotes.
Third, you may not want your entire Logos library in Obsidian. Now is the time to filter out the items you want.
Create A Handlebar Template
Handlebar templates match data in CSV fields/columns to fields in your Obsidian notes. Here is the one I am currently using.
—
Author: “{{Authors}}”
Title: “{{Title}}”
tags:
ResourceType: “{{ResourceType}}”
type: Book
media: eBook
owned: Yes
location: Logos
publish: “{{PublicationDate}}”
ResourceID: “{{ResourceID}}”
Series: “{{Series}}”
Subjects: “{{Subjects}}”
status: ToRead
date_added: <% tp.date.now(“YYYY-MM-DD”) %>
date_started:
date_finished:
MyTags: “{{MyTags}}”
CommunityTags: “{{CommunityTags}}”
aliases:
– “{{Title}}”
—
# {{Title}}
Most of the fields are self-explanatory. I chose to put much of the data in the frontmatter so I can use it for Dataview queries. The fields ‘type’,’media’,’owned’, and ‘location’ help me to know where I can go to find the actual resource should I want to read it or watch it again.
I’m debating on the default value of ‘status’ for this import. I have a library of 2200+ resources and I don’t necessarily want to read all of them – only know I have them on hand to refer to if I want.
Let’s talk a bit about tags. ‘tags’ is a specially-defined field in Logos. I tried a few different ways to get it to inherit the values on one of the columns in my import file, but the imports would always fail. So, I had to leave it blank. I think that “{{Subjects}}”, “{{MyTags}}”, and “{{CommunityTags}}” are clear candidates for this, but I didn’t figure out how to preset it in the short time I was playing around with this.
If you are going to build your own Handlebar template, I would suggest adding one field at a time and testing your import until you get the results you expect (more on that next).
Test Your Import
Rather than import everything in one fell swoop the first time, I would suggest making a sample of your import file (maybe 10-15 lines) and testing your procedure until you are satisfied with the results. The importer has no debugging or logging; it either works or nothing happens.
To start the import, click the icon on the left that looks like a magnifying glass. Set the import file and the template file. Here are some notes regarding other fields you should pay attention to.
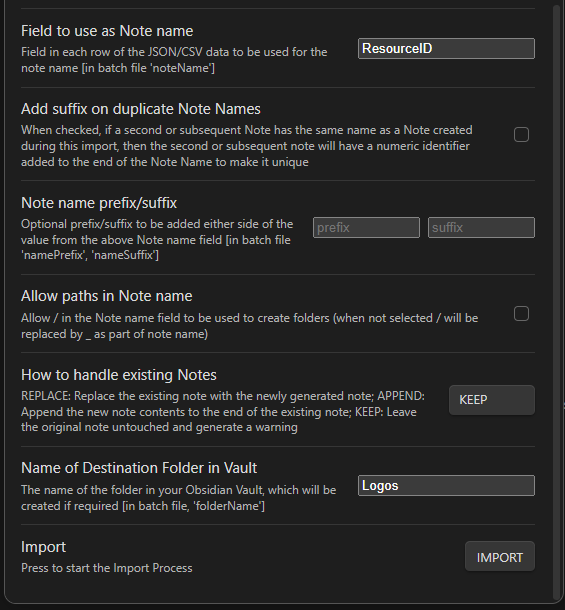
I would suggest using the ResourceID field as the Note name. This is because Titles are not unique in Logos. If you use the Title field, some of your items will get skipped unless you click the “Add suffix on duplicate Notes Names” field. The problem with this is you then have to go do some cleanup on the file names later. So, to avoid this, I suggest using the ResourceID as the file name. And, if you put the Title in the aliases field (like in the template above) you will still be able to reference the Note by the title of the book in your Logos Library.
I would also suggest setting the Destination folder to something that doesn’t currently contain any notes when you do the import. You will likely have to import and delete these notes several times before you get a result that looks like what you want. Putting the results into their own folder makes this process much easier.
Final Import
Your final import will take a few minutes to complete. I imported around 2200 resources on a 6th-Gen i5 with 16 GB of RAM and it took about 3 minutes. The only way you will know that the import has finished is to monitor the folder you are creating the Notes in. When the number of items stops going up, the import has finished.
Final Thoughts
Ultimately, I want to turn all of the elements in the “Subjects”, “MyTags”, and “CommunityTags” fields into tags that Logos will recognize. This is done by preceding each of the words with a hashtag (“#”). Next up is for me to figure out a way to do this in bulk.
Obsidian also has a cool feature with tags in that you can construct them into a hierarchy. For example, if one article was tagged with “doctrine/God/Eternity” and another was tagged with “doctrine/God/Aseity”, a query for “doctrine/God” would give you all the notes in the two subcategories.
I’m open to suggestions on improving this process. Feel free to comment below.